
Relationship markers can be a powerful tool for adding detail about a relationship between two records. Relationship markers are discussed elsewhere, however, a detailed description of the mechanism for importing relationships from a CSV file has not been outlined (for more on importing data into Heurist see here).
Relationship markers are simply that – markers of where a relationship is meant to exist. They cannot, in themselves, be imported since they contain no data. What you are actually importing is a relationship record. In order to import relationship records, you need a CSV file which at a minimum contains Heurist IDs (H-IDs) for the source and target records, as well as the terms describing the relationship (they may also contain dates and other information). These terms should generally match terms in the vocabulary of a relationship marker field linking the source and target record types – we strongly recommend that all relationships in a single import file are between the same two types of record – so that the relationships will show up in that field. New terms can be added on-the-fly whilst importing, but you won’t have control of which vocabulary they end up in and they will then need moving to the appropriate vocabulary so that they show up in the relationship marker field.
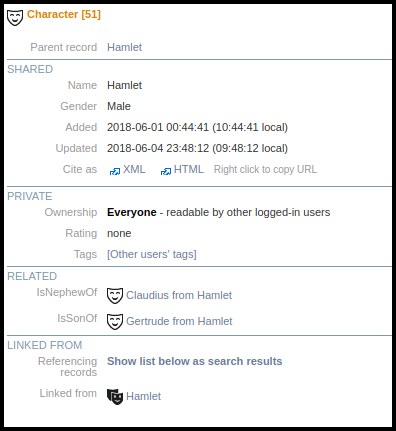
In the example shown above, we can see that Hamlet is the nephew of Claudius and the son of Gertrude.
The Heurist IDs (H-IDs) can be obtained by exporting records to CSV file(s), using the Export tab and selecting CSV file. You should also include any additional fields that will assist you to identify your records (such as Name). This will enable you to identify which H-ID belongs with which record. Once you have the H-IDs, create a CSV file which has a column for the Source H-ID and a column for the Target H-ID. You should make sure that the source and target record types fit the model you’ve defined and implemented using relationship marker field(s). The source and target record types can be the same, eg. Persons can relate to Persons with family relationship types. Person’s can relate to Employment records, in which case the Source H-ID would refer to the Person record, whilst the Target record would be an Employment record. The columns for Source H-ID and Target H-ID must have a column name which includes “H-ID” somewhere in the name so that Heurist recognises it as a Heurist ID column.
As well as Source H-ID and Target H-ID, it is necessary to include a column term which defines the relationship. These terms depend on the vocabulary used by the appropriate relationship marker. For example, “Related Persons” uses the Family vocabulary and records family relationships, such as “ParentOf”, “ChildOf”, “SpouseOf”, “CousinOf” etc. An employment field might use a different vocabulary which uses terms such as “was employee at”, “was manager at”, “owned” etc. Only these three columns are required, although, of course one can include more if desired. It is possible to add data to match other fields in the “Record relationship” record type, including Start Date and End Date for the relationship, a Short Description etc.
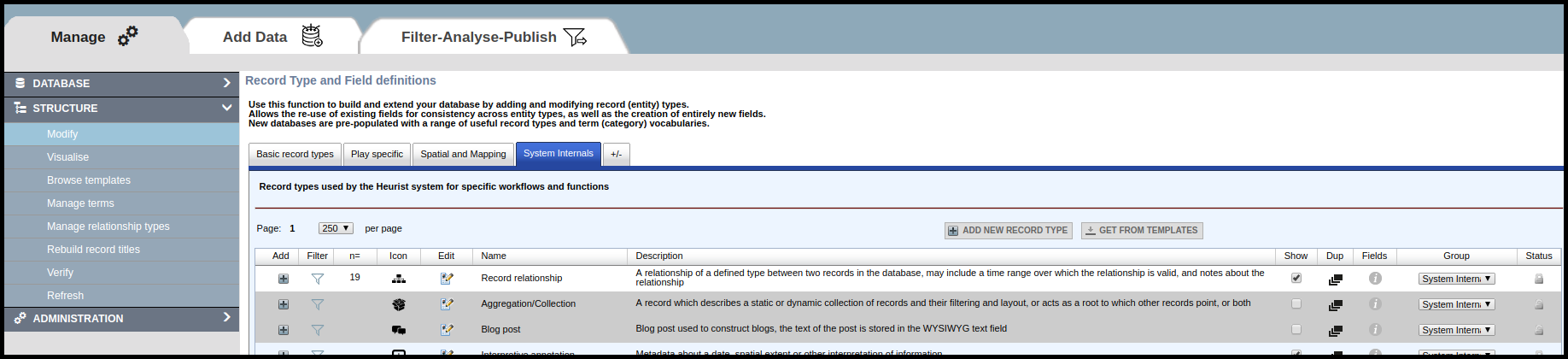
Before importing the CSV file created for the relationships, it is important to ensure that the record type “Record relationship” is active (i.e. able to be displayed – it does, of course, function regardless). You will find this record type in the tab called “System Internals” in any Heurist database. To make the record type active, click on the checkbox under “Show” (see screenshot above). This will also change the background of record type from grey to white, as shown above. This will enable “Record relationship” to be selected as the Primary record type for the CSV import.
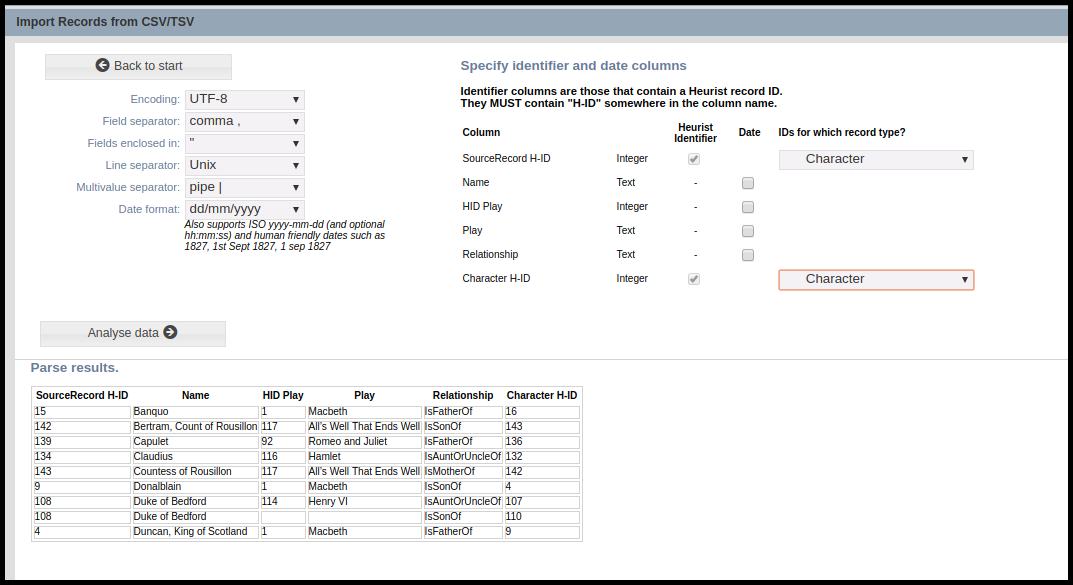
Once the CSV file is ready then select Import Delimited text (csv, tsv) in the Add Data tab. The CSV Import wizard will open in a popup window. Upload the CSV file and select Analyse data. As shown in the screenshot above, Heurist will automatically select the checkboxes next to the H-ID columns in the CSV file; you should then identify the record type associated with both the Source and Target H-IDs. In the example shown above, both H-ID columns refer to the record type “Character”. Note that additional columns of data are present in this file, although they are not needed for this import. These additional columns can be ignored.
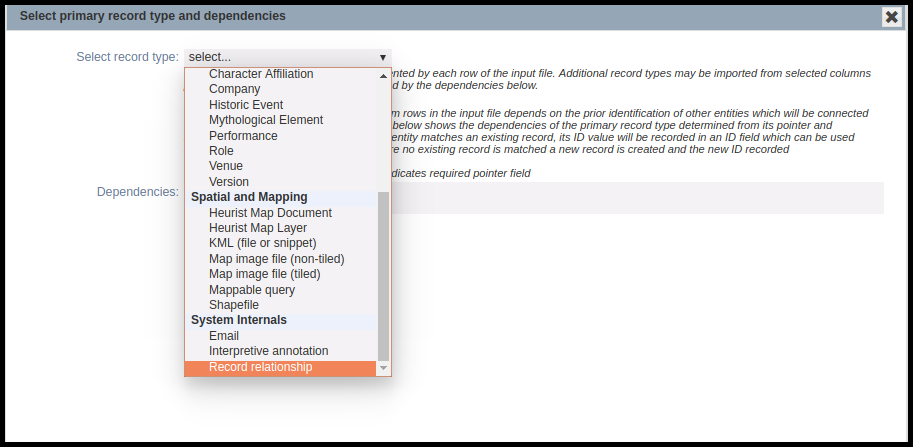
Continue to select the Primary record type. It is important the “Record relationship” record type is selected from the System Internals group (see above). Do not select the record types associated with either the source or target records. In this example, we are not importing any dependencies, therefore the dependencies can be left unchecked. It is probably best to match on the Source records, using the Source record pointer, however, any non-ambiguous match is fine. Then match the fields for import. At a minimum these need to be the Source records (as a pointer field), the Target records (as a pointer field) and the column containing the relationship vocabulary terms. Continue with the import process as for other CSV files.
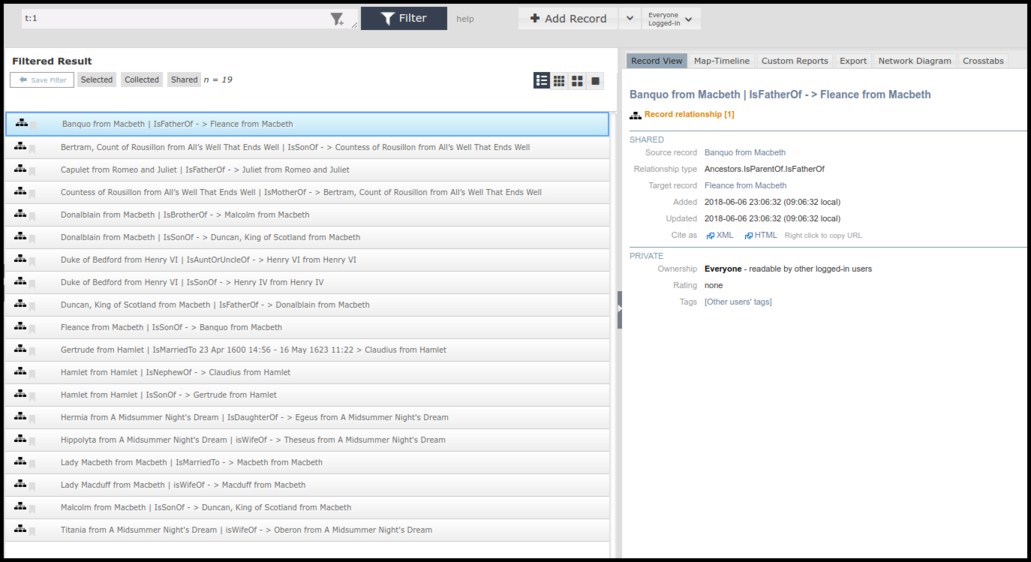
The screenshot above shows the resulting relationship records imported into the database. Note that the filter “t:1” returns all relationship records.
As stated above, Start and End dates for the relationship can also be added. These can be imported as separate fields in the CSV file. If edited manually, times can also be attached to the start and end dates.