
Defining entity dependencies in spreadsheet import
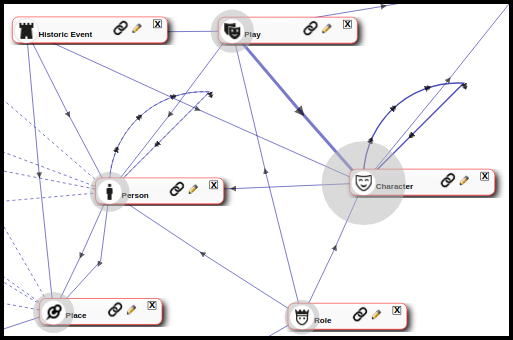
It may be tempting to think that a spreadsheet describes one type of entity – for example, a Person, Organisation, Interview, Work, Document, Image, Event, Structure, Sample, Context etc. But in practice this is quite rare. While the primary subject of the spreadsheet – the one represented by each row – may be quite obvious, the rows often contain secondary entities on which the primary entity depends. For example, a row describing a Person could also include the names of their parents, wife(ves) or husband(s), their place of birth, the school and university where they studied, organisation(s) to which they belonged, and so forth. A record of a theatrical Performance may include the work performed, the author(s), the edition used, the director, the theatre in which it was performed, the theatre company and perhaps a list of performers paired with the characters they played and grants and sponsorship received. For example:
FamilyName, GivenNames, FatherFam, FatherGiv, MotherFam, MotherGiv, BornAt, BirthCountry, BirthDate, School, StartSchool, EndSchool, University, StartUni, EndUni, MemberOf
Smith,Jane, Smith, Bill, Richards, Margaret, Newcastle, UK, 17/6/1968, Newcastle Grammar, 1980, 1984, UCL, 1993, 1996, Red Cross
Smith,Tom, Smith, Bill, Richards, Margaret, Newcastle, UK, 17/6/1964, Newcastle Grammar, 1976, 1980, Liverpool University, 1981, 1984, Freemasons|Rotary
These additional columns are not just attributes of the entity being imported. They are typically independent entities – another Person, a Place, and Event etc. – which have their own set of attributes. The same secondary entity is often linked to multiple primary entities and should be recorded only once in the database to avoid redundancy. The link between the primary and secondary entities may be repeated eg. a person may have lived in several places, many performances occur at a single theatre. The links may also be of a particular type and have a starting and ending date.
For all of these reasons these links will typically be represented either through record pointer fields (for simpler relationships) or through relationship records* (where detail is required about the relationship itself), with the pointer or relationship linking the primary imported record to another entity (Person for parents, partners, authors, directors and performers; Place for place of birth; Organisation for place of study; and so forth).
* Relationship records are defined by adding a relationship marker field to the primary entity, which sets up the target record type(s) and the set of relationship types which are allowed.
By linking to another record with a record pointer field or relationship record, it becomes possible not only to record several alternatives (a person may have been married more than once or studied for more than one degree), but also to record further information about each of these secondary entities eg. dates and place of marriages, courses of study followed and results. Secondary entities may also be quite conceptual, such as instances of education, occupation, religious or military service, residence etc. (such as the combination of place, dates, type, notes etc. linked uniquely to a particular person, which we call Life Events).
In order to import the primary records described by the spreadsheet rows, for example Persons, we first need to match (if the entity is already in the database) or import (if it is not) each of the entities on which the person’s description depends. By matching or importing a secondary entity we set the record ID for that entity, which can then allocated to a record pointer field in the primary entity or the target of a relationship record. Note that secondary entities can have their own dependencies, so this process can get quite involved.
Note also that references to primary and secondary entities are ONLY in relation to a particular import. The entities, once imported, do not have any markers of primary or secondary character.
Heurist offers a ‘wizard’ approach to manage the process of separating out all the secondary entities, identifying those which exist in the database, importing them and setting up links between them.
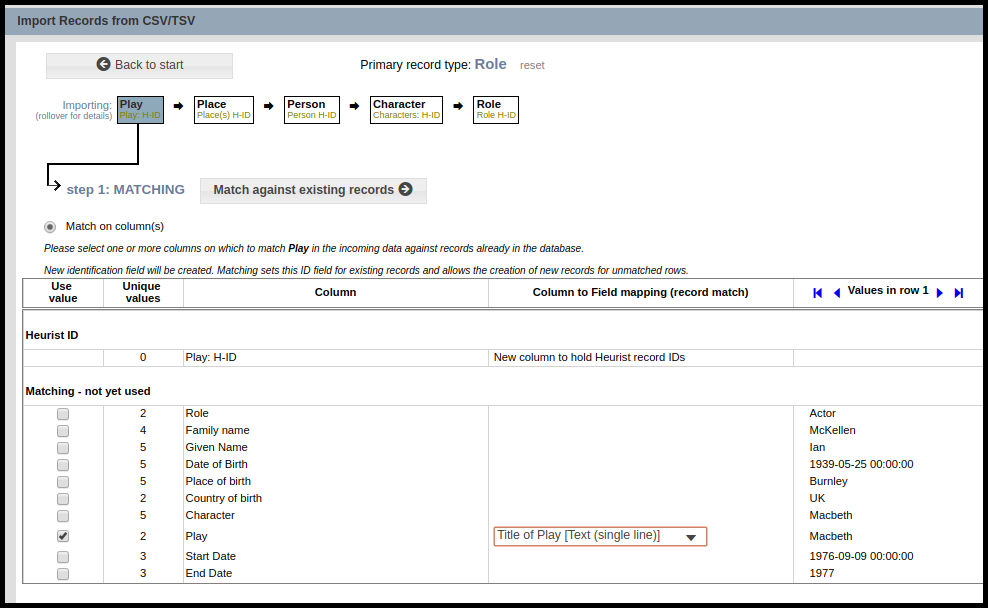
Where possible we recommend splitting off commonly/repeatedly used entities such as places, institutions and people into separate files, importing these files, and then adding the Heurist IDs as a column to the primary table with “H-ID” in the column name eg. “Birthplace H-ID” (after adding and checking the Birthplace H-ID values, you could then delete the birth place column(s)). This will cut down on the number of steps in the wizard which can be overwhelming for new users.