
A unique solution to the data management needs of Humanities researchers
")
HEURIST is a research-driven data management system that puts you in charge, allowing you to design, populate, explore and publish your own richly-structured database(s) within hours, through a simple web interface, without the need for programmers or consultants. We provide full support, including round-the clock email support, live workshops, online tutorials and access to a global network of Heurist users.

")
HEURIST is agile. You can build a capable database and a CMS website in a matter of hours, starting with a simple design and building incrementally as needs change, modifying the live database on-the-fly. Use our free servers, which support hundreds of projects and are centrally maintained. It is easy to migrate data in and out of Heurist, because of its standard, open-source design, and its ability import and export common data formats.
Want to get started with Heurist? Try our
")
HEURIST is flexible. It can effectively store, analyse and publish a wide variety of Humanities data, whether you’re a musicologist collecting songs, an archaeologist collecting objects, or a historian collecting events. HEURIST can handle everything: text, numbers, hierarchical classifications, images, video, spatial data and dates (including non-western and approximate dates). Rich relationships between records can be built with ease.
Want to see how others use Heurist? See our
")
HEURIST gets results. You can perform sophisticated filtering, then save, organise and publish the results as interactive maps, timelines, network visualisations, cross-tabulations, lists, custom reports, and a range of export formats, all of which can easily be embedded live in a website created in Heurist’s internal CMS, or in a personal or institutional website.
Not sure what you need?
Designed by researchers, for researchers, Heurist reduces complex underlying decisions to simple, logical choices.
You can create Heurist databases at no charge. Databases created on this service can be used to support a research project as they will be maintained as long as they are in use.
Heurist is entirely non-profit. It is, and will remain, free to use.
However, to provide this service we need your financial support
If you are planning to create a database for an internally or externally funded project we ask that you include significant funding to support Heurist in your project budget. Our experience in setting up project databases and websites will more than pay for itself in helping you with rapid setup and guaranteed outcomes; if Heurist doesn’t already do everything you need, we are in a position to add new features which become part of the standard system contributing to the general good. Please contact us to discuss a suitable budget, special features required and for provision of appropriate text for inclusion in grant applications or internal budgeting.

Low Threshold
Heurist’s intuitive web-based interface is uniquely tailored to the data needs of Humanities scholars, rather than to business or scientific data. The ability to import, and then adapt, a library of useful structures (templates) developed by the Heurist Team and other users is both a great time-saver and a powerful force for standardisation without compulsion. Annotated forms make it easy to build your data structure, add and edit data, analyse the data and publish. Any confident researcher should be able to build a fully-functional database in minutes, and develop a complex database tailored to their needs in hours or days, all without programming.
more...
PROBLEM:
You need: a proper database, several entity types, relationships between entity types, full control of your information, access from multiple locations, selective sharing with colleagues, compatibility with standards, sustainable and archivable data, free and open source. You need to be able to: change the database structure at a moment’s notice, import existing data, reference external data, have assistants safely enter data online, export data for analysis and visualisation, and publish data selectively to a website. And: you don’t have a technical team, you don’t have much/any funding, and you need it today!
SOLUTION:
Heurist resolves the problem that eResearchers have typically faced in managing their complex research data coming from different sources and in different forms (e.g. bibliographies, research notes, images, map data etc.).
As an alternative to either building a dedicated database (time-consuming and expensive) or knocking together an ad-hoc solution using whatever tools are to hand (creating a ‘silo’ environment), Heurist offers researchers an integrated, free and Open Source single web-based tool to handle all their data.
Without investing in technical expertise, researchers can use Heurist’s simple forms (with tips) to rapidly build their own, complex databases with a host of advanced features not normally available without special programming, including the ability to: easily create new entity types and relationships (record linking); add and modify fields; manage term lists; import, edit (including bulk edit) and verify data; access information from anywhere and share data (selectively) with colleagues; visualise data through automatic mapping, timelines and network diagrams; modify structures record on-the-fly; and export/publish data.
And users can quickly get started by leveraging off existing work, through the reuse of preconfigured data schemas (templates) created by other users and stored on a central repository
To get started, you can use the free service hosted at the University of Sydney Data Centre (https://heuristplus.sydney.edu.au/) or one of the other listed services, or set up Heurist on your own server or cloud service in a couple of hours. Databases are easily migrated between servers.
Adaptable
Heurist’s set of powerful, robust and adaptable features extends its application to a wide range of scenarios and provides scope for multiple applicabilities. From a single system, Heurist users have the tools and flexibility to create a wide-range of solutions, only restricted by their imagination.
more...
Here are some of the things Heurist has been used for (in no particualr order):
—-
- HISTORICAL RECORDS AND PROSOPOGRAPHY
- A text and media-rich public encyclopaedia of historical content for a city, with maps and timelines
- A visual representation of a city’s historic crimes and criminals
- A record of ballads, pamphlets, tunes and people involved
- A history of indigenous sports linking people, places and events
- Interlinked life histories with rich photographic and documentary material, and timelines
- Index of historic maps of a major city
- A collection of medieval menus, recipes and ingredients
- Documenting and mapping the immigration history of a city
- History of venues, seasons and performances of a theatre company
- Biographical information for professional cohorts
- MODERN HISTORY / CONTEMPORARY
- Records of grants and projects for an agency
- Records of educational service providers and their services
- Encyclopaedia of flora information for a specific area
- Records of religious violence and foreign intervention
- Movies on streaming services with participants and classifications
- Early movies with cinemas and screening schedules
- Organising information on political movements
- ARCHAEOLOGY
- Photographic collections from archaeological survey of a country.
- Excavation phases, contexts, structures, finds, and type specimens across multiple excavations
- Field survey and excavation data collected via Android tablets
- Archaeological site registers – specific region to countrywide
- Photographs and videos of historic agricultural practices linked to landscape and social context
- A collection of relevant research information about the boundaries of Ancient Mesopotamia
- Stratified excavation data from major sites
- LIBRARIES AND LITERATURE
- Linked annotation and publication of literary work
- A multillingual glossary of historical taxes with detailed descriptions and classification
- A study of mediaeval scholia on Homer
- History of library membersghip and borrowings
- Book studies – sales and confiscations
- Tracking mediaeval bibles
- Tracking Jesuit translations
- ART HISTORY
- An interlinked set of descriptions for artists, paintings, collections, and villages for a country
- Artwork collections
- HERITAGE AND URBAN STUDIES
- Information on buildings, people and events on campus for use in an undergraduate course
- Trans-national immigration history and heritage buildings
- ADMINISTRATIVE
- Bug tracking and work allocation system
- Rental management database
- Heurist’s online help system
- Projects and contacts tracking system
- Society membership records
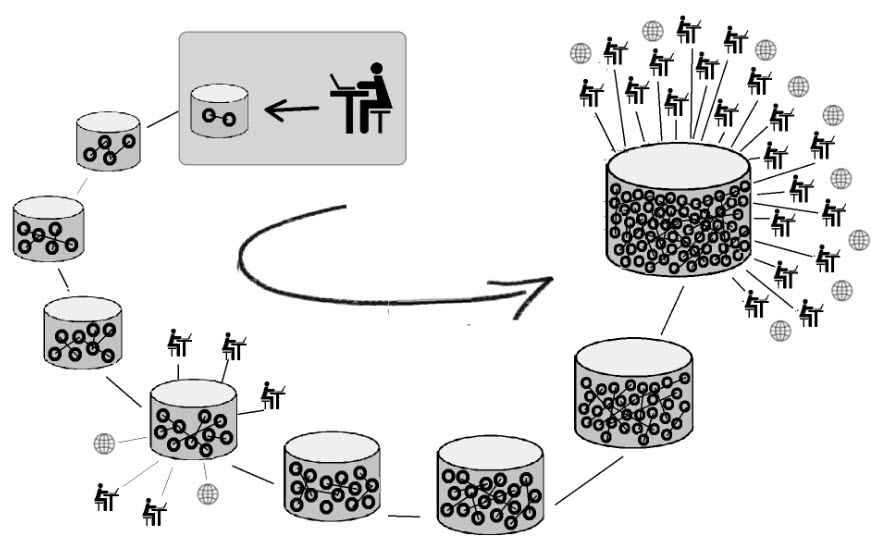
Incremental
Heurist’s complete database-design environment, incorporating sophisticated database facilities, lets you manage complex Humanities data and its structure in an evolving manner. Get started immediately with something small and simple, and then modify and extend your database structure as you become more comfortable with it or your data model and needs evolve.
more...
New databases take only a few minutes to set up, although an investment in downloading well-designed data structures (templates) and in fine-tuning these (e.g. eliminating unneeded fields, setting field labelling, field order, field widths, field requirements and repetition of values), will lead to a better user experience.
And you can continue to evolve your database design at any time without affecting your existing data.
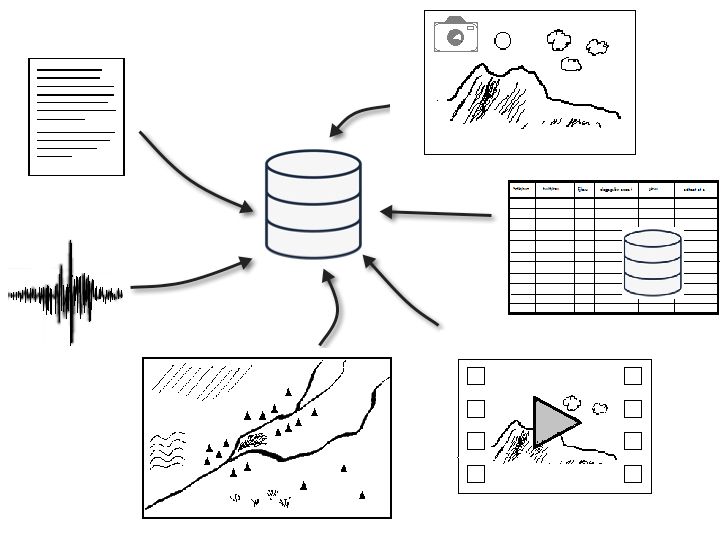
Existing Data
Heurist’s import feature takes you step-by-step through the import of structured tabular data, while accommodates a range of sources and different data sources: CSV, SQL, KML, Bibliographic, Media, with entity matching on one or more key fields and merging of data.
more...
Large volumes of images and other multimedia files can be quickly loaded in bulk and indexed. In addition, some forms of data can be synchronised; for example, Zotero bibliographies can be synchronised to connect objects of study with full bibliographic references.
Heurist supports the import of KML (Keyhole Markup Language) data, a file format used to display geographic data in an Earth browser such as Google Earth.
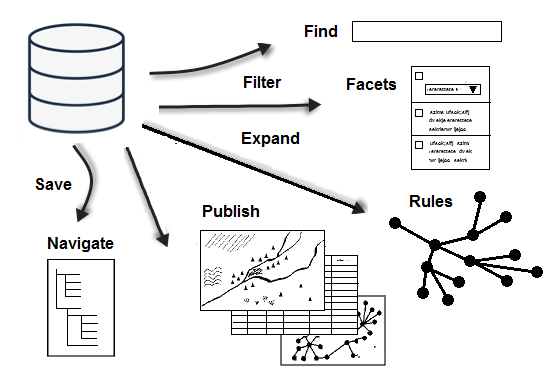
Sophisticated Search/Filter
From simple text searches to faceted searches and rulesets for retrieving a network of connections, Heurist provides numerous options for searching and filtering databases. Search filters can be saved and re-used to analyse or publish data subsets.
more...
A quick search tool assists you in building editable filter expressions, to target particular record types, fields and values from controlled lists, without needing to know the required syntax. Refine your search criteria through: partial string matching against record properties (titles, tags, keywords, special fields etc.), comparison operators (e.g. Greater Than), specified types or bookmarked; negation; and sorting records (by text, field, date, popularity, rating, etc.). An advanced search/filter tool is available to build more complex filters based on the Heurist search syntax.
Additionally, Heurist lets you expand/refine the search result-set through:
Rulesets: Expand the search result-set through one or more rules, each of which describes the set of pointers and relationships (including reverse pointers) to follow from each of the records in the initial result-set in order to add related records to it. A rule can comprise several steps out from the initial result-set.
Faceted Searches. Selectively refine the result-set based on selected data properties.

Filters (including rules and access settings), Rulesets and Faceted Searches can be saved and reused, for grouping and sharing records for particular purposes.
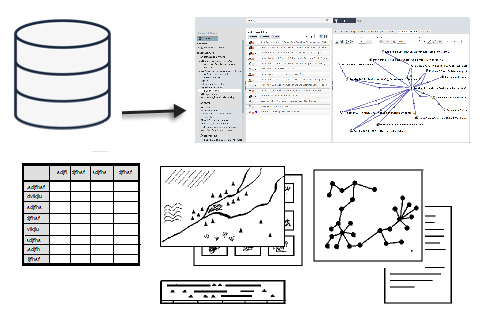
Analysis & Visualisation
Rule-based network expansion, cross-tabulation analysis, interactive maps, timelines and network graphs provide summarisation and visualisation of data patterns. Various output formats and user-defined custom reports can feed subsets to mapping, graphics, statistics and other visualisation packages.
more...
Heurist has a rich-set of tools for analysing your data structure and data.
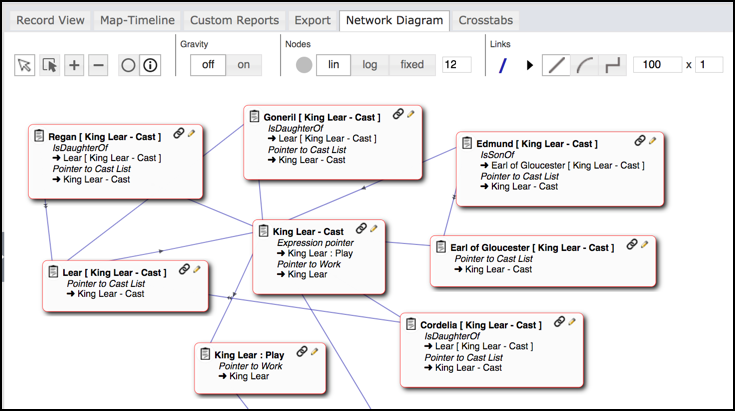
You can visualise the structure (schema) of your database, in both list form and as a network diagram. The network diagram provides an interactive (spring-loaded) visualisation of your database’s record types. Record types are shown as nodes, and the connections (pointer fields and relationships) as the links between nodes (edges). You can update links (relationships) directly via the diagram by simply drawing new connections. Data result-sets can also be visualised through a data network diagram.
A map & timeline view shows geospatial and timeline data stored for ‘map documents’ attached to one or more records.
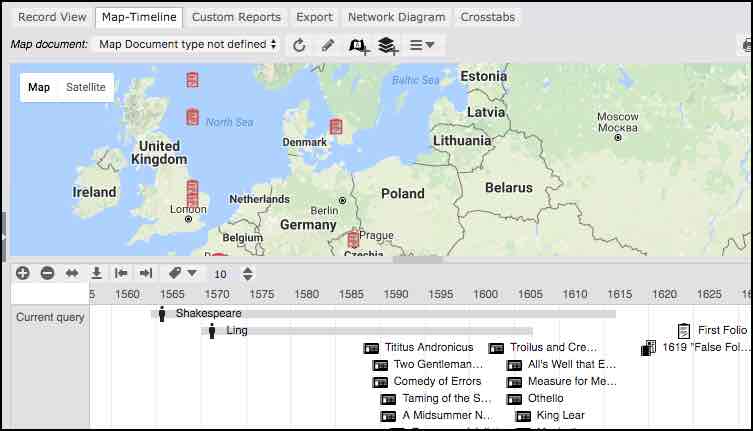
Heurist provides basic cross-tabulation (of up to three fields, with counts and percentages) which can be applied to the result-set, allowing segmentation of the data.
Data can easily be exported from Heurist in a variety of text formats, including comma and tab separated files and GEPHI GEFX. Custom analysis functions can also be added to the interface with PHP programming.
Collaboration
Whilst securily maintaining your personal and private information, Heurist provides an integrated workgroup environment for sharing and collaborating online with other users, through workgroups, sharing, tagging, saved filters, messaging, record-level ownership and publishing control.
more...
In addition to being used by individual researchers who wish to create and use a database for their own projects, Heurist’s shared collaborative knowledge-space allows project members to share an overlapping set of records in a single database (securely available online) and communicate with one another around those records through a range of communication channels:
Workgroups
By setting up workgroups and adding members to workgroups, Heurist can be used for group projects, with tasks divided between those designing the database and those populating and searching within it. Members can collaborate on research projects by sharing research data/functions with their colleagues (i.e. fellow members of the workgroup) through a range of collaboration tools. Members can display a subset of record types for specific groups of users, protected from modification or viewing by non-members.
Bookmarks
Within shared databases, researchers can ‘bookmark’ sets of records (their own records and other user records of relevance) to develop a personal subset of the shared database. Bookmarks are a way of separating private information about a record and shared information about a record; for any bookmarked record, you can attach information, either for your own personal use or for sharing. And you can search specifically within just bookmarked records, to quickly find commonly used records.
Bookmarks incorporate many useful features:
- Add and (optionally) share personal notes.
- Engage in a discussion with other workgroup members.
- Rate records (sortable in search results).
- Join group discussions per record.
- Leave comments for others to reply to.
- Add web links, web pages, images and geographic location to shared records.
- Attach personal password reminders to bookmarks for password protected resources.
- Notify other users of records that might be of interest to them. Or attach email reminders to shared records to notify a user or workgroup about multiple records of interest at specified intervals (specific date, daily, weekly, monthly, yearly).
Tags
Set workgroup tags (tag records with meaningful, multiple search keys) and share these among workgroup members. Tag creation includes: multi-word tags, tag disambiguation, clickable lists of suggestions, instant searching by tags (including partial matching), and following tags to related records. Manage tags through popularity, deletion, combining and renaming.
Record-level ownership and publishing control
Control workgroup members’ access and permissions, as well as access to published reports.
Web Publishing
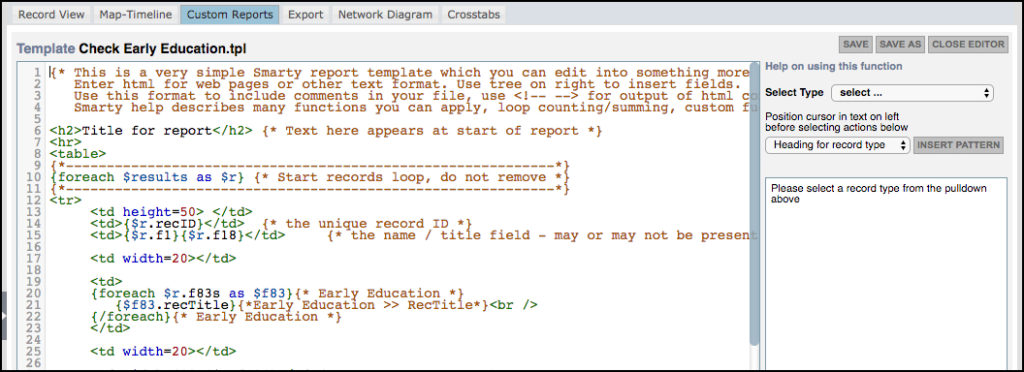
Use Heurist’s Report Builder to present your data online. Incorporate interactive visualisations into your website or blog. You can build a website using Heurist itself, or publish your reports using your own CMS or blogging site. Heurist will even write the HTML/JavaScript required for your site, allowing you to copy-and-paste live content from the database into any website with no programming required.
more...
The Publish option can be used to copy a link to your published report (either the URL or JavaScript wrap), in order to provide access to the report outside of Heurist. Access will be based on user database access permissions and the permissions you have set for each record.
Reports can be run on demand or based on a user-defined schedule (which can be used to set up a call for writing reports to file: HTML and JS.
Sustainability & Access
Sustainability of complex digital resources is a critical issue to anyone committing their research data to digital format. To this end, data is stored in a fixed format in the most widely used Open Source SQL database, allowing independent access into the future through any programming tools. Heurist also supports fully-documented generic SQL queries, XML feeds, XSL transforms, and creates JSON, XML & SQL archive packages.
more...
Heurist databases have high sustainability—of the order of decades—for the following reasons:
1. Heurist is built on MySQL, the most widely used Open Source relational database server today (used by many major applications including WordPress, Drupal, Wikipedia, Facebook, Twitter, Tumblr, Flickr, YouTube among others).
2. All Heurist databases have an identical MySQL structure, which is internally documented with consistent field-naming conventions and a concise and informative comment section on every field.
3. The structure, data and logic of a database built in Heurist is built into the database itself, not the software; the structure, data and logic in a Heurist database are fully self-documenting. This contrasts with typical database applications where the database structure maps to the domain of the application and the application software is essential to using, if not interpreting, the content. Such applications are inherently unsustainable and probably have an unmaintained life of less than 5 years. The data in Heurist databases will be accessible and comprehensible/usable via standard SQL as long as MySQL databases are readable, which is likely to be a matter of decades.
4. Heurist itself is Open Source (available on Google Code), and built with PHP and JavaScript, among the most widely used Open Source programming languages on the web.
One-click creation of sustainable archive package: Database owners/managers can export the complete contents of a database to an archive package, consisting of: a text file containing a MySQL database dump (the database rendered in SQL statements) which can be reloaded into any recent MySQL server (or other SQL server with a bit of work); a text file containing an XML rendering of the database content; any uploaded files (text, images, videos, spreadsheets etc.) in their original format; a textual description of the Heurist database structure.