FAIMS
Site Overview
FAIMS (Federated Archaeological Information Management System) is a $950k eResearch Tools project launched on 5 June 2012. FAIMS is led by University of New South Wales in collaboration with participants from 41 organisations, including universities, archaeological consultancies and heritage agencies in Australia and overseas.
The goal of FAIMS is to assemble a comprehensive information system for archaeology. This system will allow data from field and laboratory work to be born digital using mobile devices, processed in local databases, extracted to data warehouses suitable for sophisticated analysis, and exchanged online through cultural heritage registries and data repositories. Existing standards and components will be used wherever possible; new ones developed where necessary.
FAIMS is funded by the ARC LIEF (Australian Research Council Linkage Infrastructure, Equipment and Facilities) scheme (2014-2015). And by the NeCTAR (National eResearch Collaboration Tools and Resources) program (2012-13). NeCTAR is an Australian Government program to build new infrastructure specifically for the needs of Australian researchers, conducted as part of the Super Science initiative and financed by the Education Investment Fund. NeCTAR is collaborating with Heurist and a broad mix of national and international technology partners and research disciplines; from scientists to historians, archaeologists, software engineers and arts disciplines.

Heurist’s Role
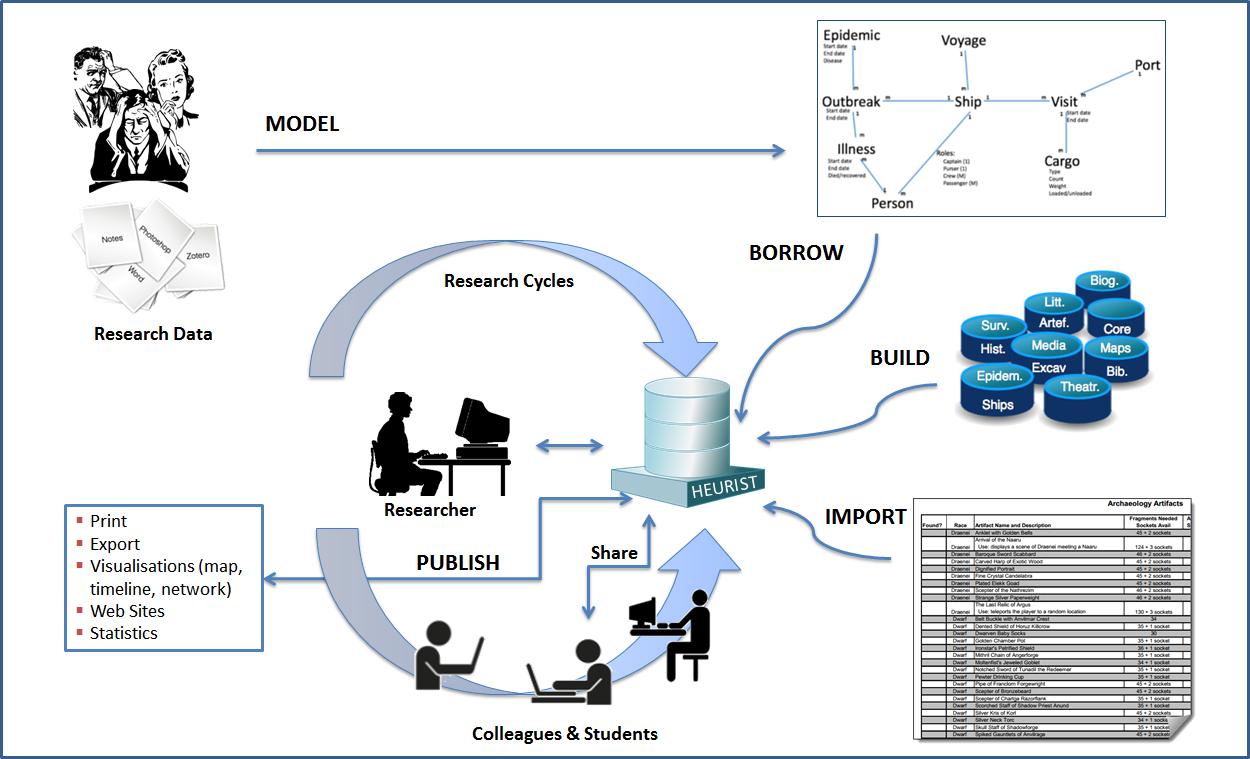
Heurist plays a central role in the FAIMS workflow. Archaeological data recording systems, for survey or excavation, are first designed as a Heurist database. Heurist then exports the XML and Beanshell files necessary to set up the FAIMS synchronisation server and Android tablet app for use in the field (these files may be used as-is, or further customised by manual editing). The data collected across multiple tablets is synchronised automatically and can then be reimported into Heurist for further manipulation and analysis. Finally, Heurist exports the data in various formats including directly inserting data in the tDAR repository (Open Context interface will be developed in 2014). This process is illustrated in the following diagram: